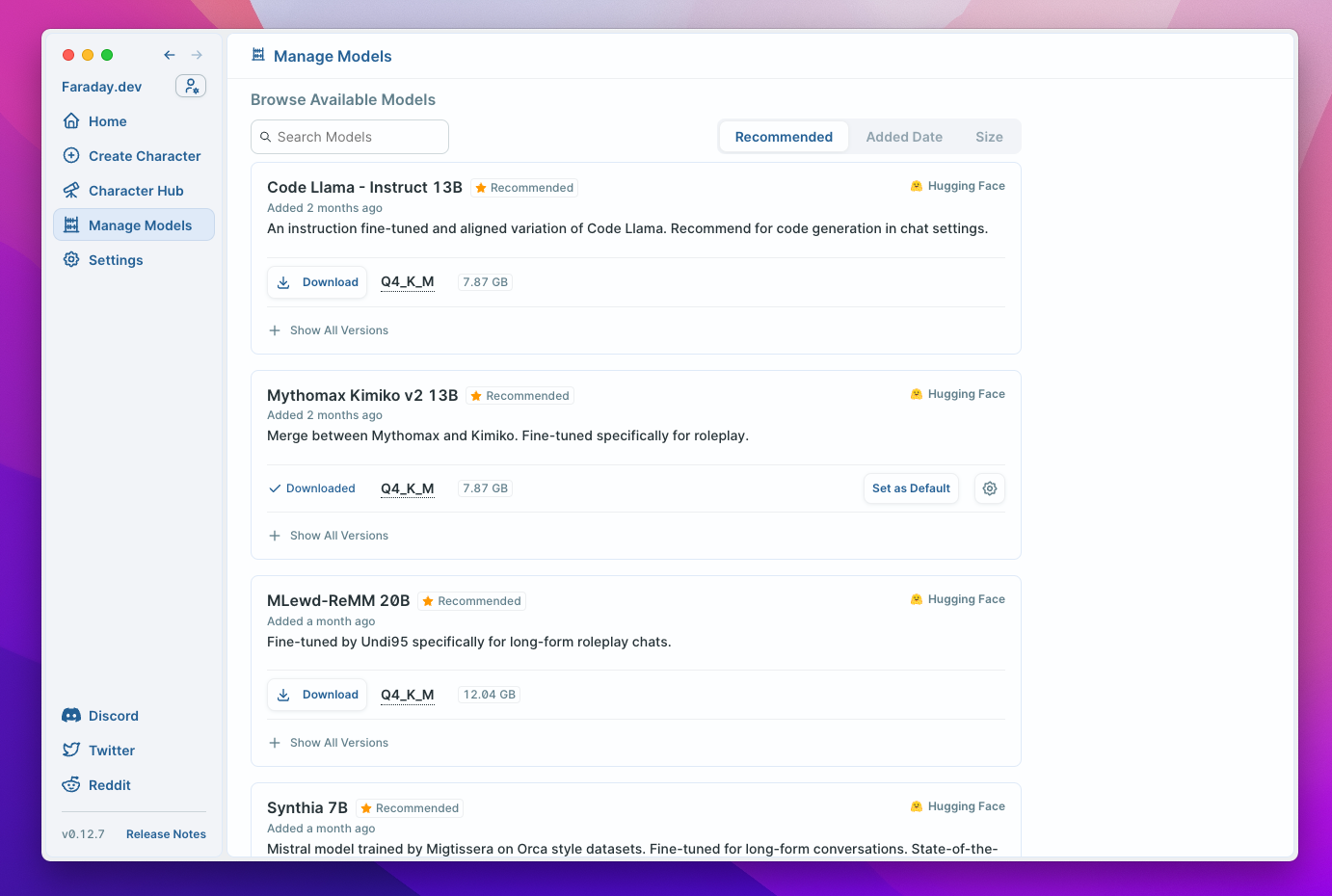
Choosing a Model
You can browse a list of models compatible with Faraday on the "Manage Models" page. Each model file can be downloaded directly to your hard drive from within the app. This list is updated frequently with new models created by the open source community.
File Formats
Faraday works with GGUF files. Each model displayed in the Model Manager is a GGUF file. GGML files may work but are deprecated.
Other file types, such as FP16, GPTQ, and AWQ are not supported.
Quantization
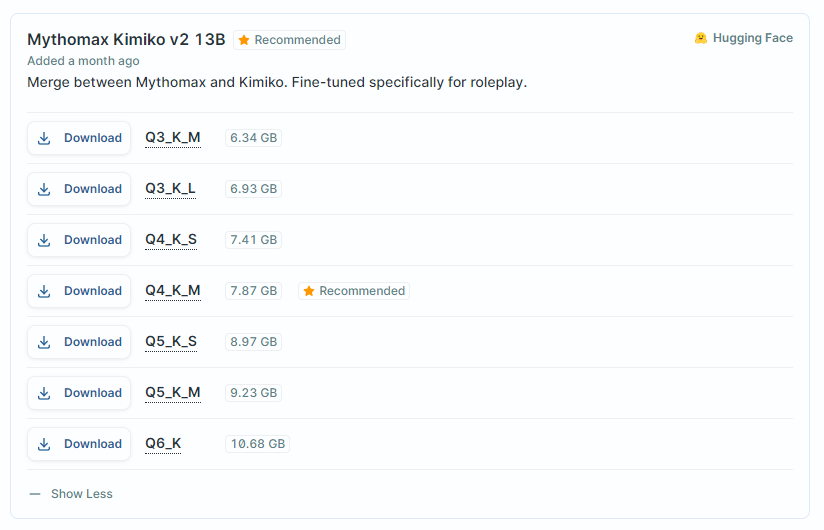
GGUF/GGML model files are quantized, which means they are compressed to a smaller size than the original model. This allows them to run on consumer hardware (such as your computer). There is a trade-off between quantization level and output quality.
GGUF files ending in “Q4_K_M” or “Q5_K_M” are currently recommended for most users. The "Q4" describes the level of quantization, the K denotes that it’s a “k-quant” and the M denotes that it’s a medium size k-quant.
Parameter Size (3B, 7B, 13B, 30B, 33B, 70B)
The "B" number represents the number of parameters within the base model. If quantization is like changing the resolution of an image, then parameters are the number of colors in the image; 70B is HDR and 3B is a gif from the 90s.
Faraday will give you some guidance on which number of parameters to use, with the most popular being 7B and 13B. A 13B should be able to run on 16GB of RAM, while a 7B should work on 8GB of RAM. For those with beefy machines, you can try your luck with a 33B or 70B model, though regardless of your system’s specs, those will be considerably slower.
Size vs. Perplexity Tradeoff
Perplexity is a metric for the quality of text generations. A lower perplexity value is better. Here is a charge comparing the perplexity of different model quantizations and parameter sizes:
